Terraform and Ansible were already Terrible in 2016
Introduction
After IBM acquired Red Hat in 2019, it recently has acquired HashiCorp. So now Big Blue not only has Ansible in its portfolio, but also Terraform.
Tech articles and social media galore, and many people have found out that if you mix ‘Terraform’ and ‘Ansible’, you end up with ‘Terrible’. Depending on your tech stack, it is a great combination: Terraform to provision cloud infrastructure, including servers. Ansible to configure those servers.
That was exactly the combination of capabilities needed by Sanoma Media Netherlands, in 2016. An in-house tool was created and, as a play on words, it was named… Terrible.
Terrible plan?
This is the first article of a series ‘Stuff From The Past (SFTP)', for which I have got a number of topics lined up. Things I have created or should not have created. Things I have worked with or wish I did not have. How did those systems age? What can be learned?
Author’s note 1: This topic was at some random place in my blog topic list. But since a lot of people are suddenly making terrible jokes, there is no better moment than now.
Author’s note 2: I did not build Terrible, but was one of its power users and worked quite closely with the team maintaining it for many years. Shout out to the forward thinkers that understood the need for this tool and made it happen!
Author’s note 3: Everything described about Terrible is based on my perspective, and my recollection and knowledge of matters. All of those might be inaccurate or incomplete.

Terrible!! BOOO!!!
Context
In 2016, Sanoma Media Netherlands had a portfolio consisting of many print magazines, and a number of digital assets that were among the largest in the Netherlands. This included Autoweek, Kieskeurig and the product I worked for: NU.nl, the largest news site in the Netherlands.
From an architectural point of view, (micro-)services were the norm. Services included a tagging service, an identity platform for customers, and platforms for images and videos. Illustrative for the services landscape: When the GDPR legislation was implemented, an organization-wide event bus was created to implement the ‘Right of access’ and the ‘Right to be forgotten'.
Product teams were autonomous and would use said services to do a lot of heavy lifiting. Looking back, I would say there was a keen understanding of what services were needed to propel the organization forward: The amount of re-invented square wheels was fairly limited.
This culture of providing services was present in the DevOps way of working as well. All application were hosted on virtual machines in datacenters. The ‘systems’ team provided tools like Puppet, Foreman, Webistrano and CheckMK. Product teams were in control of configuring their infrastructure, using puppet modules provided by the systems team. A model of ‘You Build It, You Run It’, backed by operational expertise.
In 2016, the current datacenter contracts were about to end, so the organization would either have to renew, or move to other infrastructure. For that reason, a ‘big IT solutions provider’, let’s call them SalesCorp, had been working on a new private cloud for quite some time. In that same period, some proof of concepts were done using AWS. Also, tools like Terraform and Ansible had been explored. Ultimately, SalesCorp did not deliver to expectations and timeframe, and the plug was pulled.
As a result, the organization faced the challenge to move everything out of the datacenters into AWS in a short timeframe of just months. Enter Terrible 1…
Terrible 1
Terrible 1 consisted of a set of services and a command-line client to interact with those services. Since the move to AWS needed to happen in a relatively short timespan, the goal was rehosting, not re-architecting. Coming from datacenter VMs, the AWS building blocks needed were very limited: EC2 instances, classic load balancers (ELB) and security groups.
For that reason, a very simple YAML schema was created that Terrible 1 would translate into actual Terraform HCL code. An example1:
product: nunl
cluster: news
environment: production
version: "v1"
hipchat: "NU.nl => AWS"
instances:
- role: lbapi
count: 3
disk_size: 20
type: c4.large
public: true
firewall:
- ingress:
port: 80
proto: tcp
cidr:
- 0.0.0.0/0
- ingress:
port: 443
proto: tcp
cidr:
- 0.0.0.0/0
Terrible 1 took care of:
- Authentication
- Remote state
- AWS account permissions
- Consistent tagging
- Executing Terraform
init,planandapplystages, and streaming output to users via CLI client. - Executing Ansible on the resulting infrastructure, and streaming output to users via CLI client.
The organization was organized in clusters, in our case: news. Clusters could run many products and each product would have several environments: production, staging, test.
A cluster admin could add products and environments, providing the repository containing the sources. Once set up, the typical workflow would look like:
terrible plan news/nunl/test <git-rev>
# Result: CLI streaming output showing plan being executed, followed by the resulting plan ID
# If deemed neccessary, or if configured to be required, ping a colleague to review the plan via hipchat
# Colleague would execute, review changes and confirm:
terrible acknowledge news/nunl/test <plan-ID>
# Change author would apply:
terrible apply news/nunl/test <plan-ID>
# Result: CLI streaming output showing apply being executed
Output of terrible plan would look like this2:
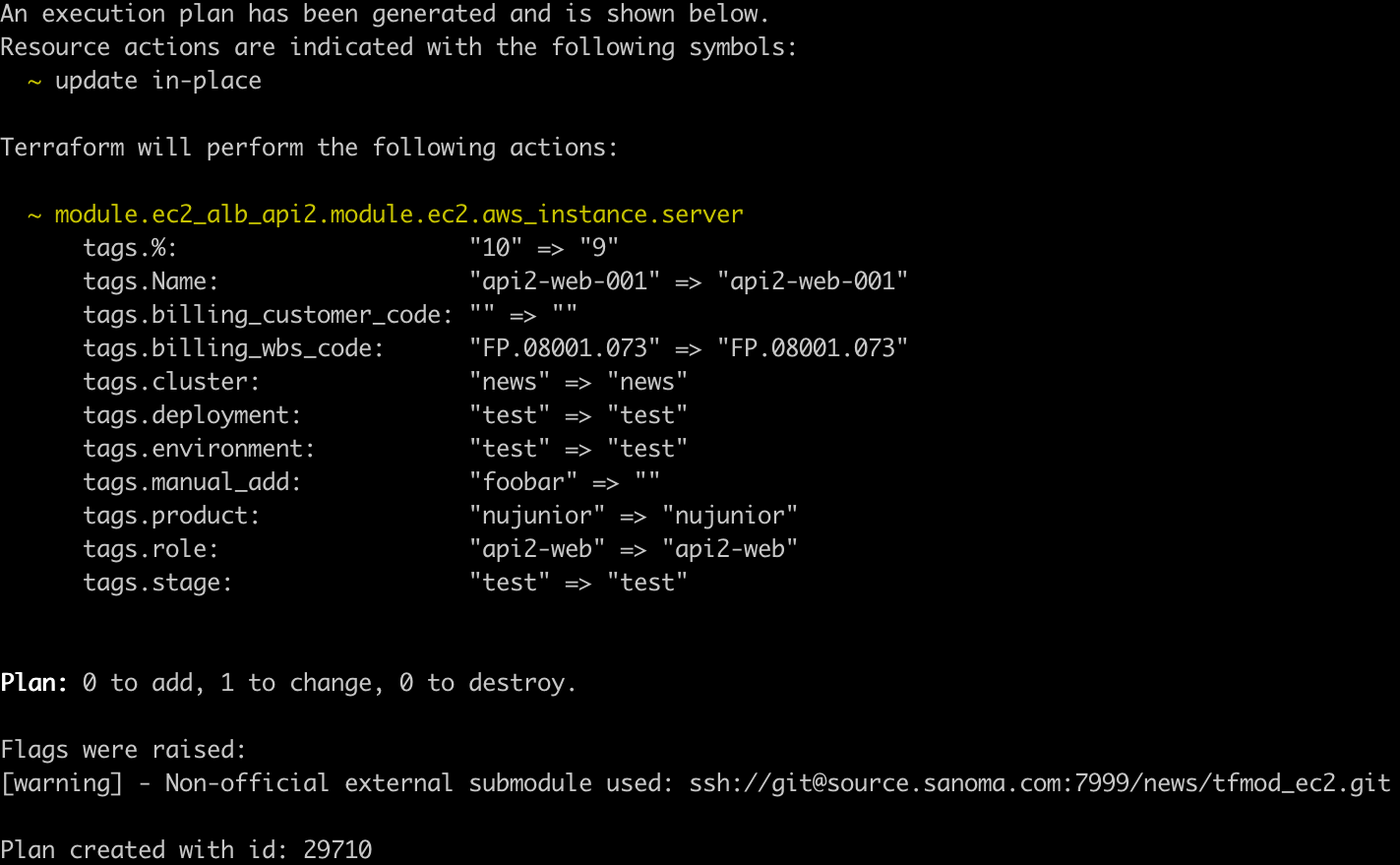
Terrible plan output
For a number of common server components, Ansible roles were created, for example Nginx, Python, Uwsgi and Varnish. Also, a ‘common’ role was provided, ensuring the systems team would be able to access servers, and CheckMK agent was installed.
The resulting configuration was more or less identical to the configuration previously set up by puppet, so the rehosting in general was a smooth process. A Direct Connect link existed between the AWS VPC and datacenter, so we could easily move applications one at a time.
Worth mentioning is that, although the Ansible roles were initially set up by the ‘systems’ team, they saw a lot of contributions by development teams in order to enable various use cases.
Terrible 2
The simplicity of Terrible 1 facilitated the quick move to AWS, since teams hardly had to learn any Terraform. Teams just needed to learn Ansible, which by most that was perceived to be much simpler than Puppet, and most Ansible roles were already present.
However, after the move, that simplicity started to become problematic:
- Although scope was limited, even for just EC2, ELB and security groups, designing a good YAML schema and keeping feature parity with AWS, proved challenging.
- Not supporting a single shared configuration, combined with environment-specific
tfvars, there was a lot of code duplication. - Now settled in AWS, quite soon other services became very interesting to explore. Most close to our technology stacks, services like RDS, Elasticache and S3 could remove a lot of operational effort, without requiring fundamentally changing our applications.
Click-ops already finding its way, Terrible 2 was created, and it did the most important thing right:
Get out of the way and put Terraform front and center
This introduced the ability to:
- Leverage all Terraform documentation found online
- Use every resource type in the AWS Terraform provider
- Collaborate on Terraform modules, similar to the Ansible roles
Over time, several features were added to Terrible 2, for example:
- Support for multiple AWS accounts
- Rest API to integrate Terrible into pipelines
- Support for more advanced Terraform usage, such as
importandstate - Ability to use Terraform to do basic AWS IAM user management. We didn’t have SSO back then, Terrible was tightly integrated with a sign-in AWS account.
No more Terrible
As always, things come to an end. Reasons, not surprisingly, include:
- Losing relevance: Platforms to build pipelines have become abundant. There are cloud platforms to manage Terraform projects, and bolting Ansible onto Terraform can now be done using the Ansible provider.
- Knowledge about the inner workings of Terrible slowly but steadily leaving the company without being re-acquired. This increasingly became a risk.
- No longer needing Ansible anyway, because having moved on to immutable infrastructure.
Eventually, mid 2023, all projects were moved to an AWS CodePipeline and CodeBuild setup. Just focusing on the Terraform code, all Terrible added, was a .tf file containing provider, backend and tags, so this turned out to be quite easy.
The CodePipeline was granted the permissions Terrible had, and a confirmation step was added to the pipeline. Lo-fi but it worked.
Looking back
Over the past eight or so years, terrible is among the tools I have used most. Acknowledging my perspective might have become a bit skewed, what were the good parts and what could have been improved?
Good parts
Empower teams
Terrible succeeded in letting us migrate to AWS in time. By empowering development teams to build their own stack, it prevented the systems team from becoming a bottleneck.
Furthermore, Terrible handled some of the more complex security aspects of Terraform by removing the need for access to the AWS account and Terraform state.
The Ansible roles, and later also the Terraform modules, facilitated collaboration and knowledge sharing, reducing the sentiment of ‘their job’.
Using Terraform plan stage
One of the strong points of Terraform is the confidence that can be gained from the plan stage: The changes that will be executed. This has been the core of the Terrible workflow from day one: It allowed anyone, regardless of experience, to contribute by starting a branch and iterate on the plan output.
At the same time, production rollouts could be protected by requiring additional approvals, ensuring a 4-eyes principle.
If I remember correctly, by the end of Terrible, plan ID was around 150k. Meaning in the 7 years, on average, more than 90 plans per day. In those years as far as I know there haven’t been occurrences of accidentally rolling out destructive changes3.
Iterate
Terrible 1 was created fast with a clear scope and goal in mind. Terrible 2 removed a lot of limitations. I’m not sure if a second iteration was planned right from the start, but looking back, it is not even that important:
- Not envisioned: Shows ability to adapt and improve, meaning agility
- Envisioned: Shows ability to start small with an MVP and deliver value as fast as possible, meaning agility
Create fast, sunset fast
As organizations grow, the ability to adapt to changes usually decreases. Not all bad, sprint vs. marathon and all, but it can stifle innovation.
At the same time, organizations having a certain size and age, usually have their fair share of ‘legacy systems’ that are dragged around forever. Once again, not all bad, you can’t rebuild everything all the time. But at some point, value and cost might become unbalanced. Having more systems simply means more maintenance.
Terrible’s lifecycle in my opinion was a good one, and did not suffer from any of the above two enterprise traits.
Could have been better
Automation relatively hard
Terrible initially focused on the CLI client. In Terrible 2 an API was added, so the process of applying Terraform changes could be automated. Since pipeline options back then were limited (UI-driven Bamboo) and the CLI process was good, there was not a lot of incentive to go that extra mile.
Authentication
When Terrible was launched, LDAP was the only sign-in system available, so that was the login method. Later Terrible was also used to manage the roles a person could assume in several AWS accounts. This turned out a bit clunky. People would need to install and login into Terrible first, before being able to get access to the AWS console. Also, granting of AWS permissions was intertwined with project permissions in Terrible, complicating this process.
In hindsight, AWS access management would probably best have been left out. Later, SSO became available, as well as MFA requirements. But since Terrible was already in ‘maintenance mode’, that never got implemented.
AWS Permissions
Terrible had a broad set of permissions in the AWS account. Least privilege would have been better but should probably have been addressed in the wider context of cloud privileges in general. The impact of this permission model at least was reduced by eventually moving to separate AWS accounts per team and environment. If Terrible was not already end-of-life, this might have seen improvement.
Far from Terrible
When running in the cloud, servers can be made simple by adopting immutable infrastructure. Similarly, with autoscaling, the concept of ‘the inventory to provide to Ansible’ disappears. So, in modern cloud setups, Ansible loses its place.
For that reason alone, acquiring HashiCorp, also bringing Vault, makes a lot of sense for IBM. And, as we experienced for many years, the combination of Terraform and Ansible can be great (not terrible!).
-
Back then, HipChat was a thing, and you could still run high-traffic news sites using DNS load balanced public VMs without immediately regretting it. ↩︎
-
We had a news site aimed at 6-12 aged kids for a while. Too bad that didn’t work out. Also: Can’t remember what my intention with the
foobartag was, but at least billing was correctly set up. ↩︎ -
I am aware people tend to become less vocal when they accidentally have destroyed an environment. Nevertheless, rumours travel fast and wide. ↩︎